淺談 SQL Server 日期時間查詢與精度進位陷阱
這篇其實之前就曾想寫,但當時最後還是決定擱置。說實話,我學生時代就不太愛做筆記,上課稍微走神一下就不知道講到哪去、接不上了,不如自己看書、自己念(至於有沒有真的理解學會又是另一回事...)。 後來開始工作,才逐漸開始寫一些給別人看的筆記。但早期那些筆記不是遺失了,就是事後回頭看覺得過時,甚至成為黑歷史,只有少數幾篇有被我搬運過來湊湊篇數。
在撰寫筆記給別人看的過程中,比較不允許有太多模糊空間,因此會查閱更多資料進行驗證、整理思緒。後來發現,這個過程可以同步迭代更新我的「心智模型」(這個詞是近期 AI 幫我校準用詞時學到的)。
其實目前我的筆記大概可以分為三類:
- 教學或實踐指南:特別寫給某些人看的教學文章。通常是看到錯誤寫法或缺少的基礎知識,寫來說明比較標準的作法為何,解釋為什麼要這樣做、背後的原理是什麼(雖然有些細節,我可能是在寫的過程中才真正釐清)。
- 情境紀錄與驗證:記錄特定情境的問題解決過程、某些想法的驗證嘗試,或曾經研究過雖然已過時但仍保留的紀錄。
- 學習筆記:學習新技術或不熟悉領域時的副產物。
去年下半年,我有大約 2~3 個月不想碰程式。直到後來才開始一邊研究新東西一邊寫,這段時間常常在想,到底還要不要繼續寫下去。
那段時間,我三不五時就把筆記丟給 Gemini、Claude 和 ChatGPT 看,問它們我的筆記是不是寫得很糟?花那麼多時間寫這些感覺沒什麼意義?
就算是我熟悉且已知的部分,即便有了 AI 輔助,實際上真的寫起來也要花上好幾個小時,甚至好幾天。
雖說只是寫興趣、更新隨緣看心情,但看到像黑暗執行緒、保哥那些常被搜尋到的技術部落格,他們的更新頻率與文章深度,就讓我覺得自己寫這些似乎沒什麼意義。有些作法甚至還被 AI 說是「非正規」(雖然我自認在野路子中已經算相對正規了),然後我又常常一忙就幾個月沒消沒息。
Gemini 它們也給了回饋,說我那些「特別寫給別人看」的筆記,架構可能真的不適合當時我想寫給的那些人閱讀。補充的基礎知識可能資訊密度過高,導致有看沒有懂,甚至讓人排斥閱讀。
而那些「糾正現有寫法或觀念」的筆記,我又需要確保這份認知的正確性——畢竟我從不覺得自己的認知絕對正確——所以得花時間查資料、測試驗證。畢竟工程師之間的文人相輕那麼嚴重,還三不五時涉及信仰戰爭。
但這就遇到一個弔詭的狀況:為了佐證,我會附上實測紀錄;但當筆記充滿大量資訊時,對某些人來說,他們不想看這些,只想看「怎麼解決」、「怎麼寫」,然後直接套用。
ChatGPT 也提到,對 AI 而言我的段落脈絡很明顯,但對於某些讀者而言,段落間缺乏過渡銜接,可能會不知道為什麼我突然跳到另一個話題。
但對於要去改善這點,我個人是排斥的。寫成這樣已經是習慣,有好幾篇甚至寫到厭世,如果還要花心力去處理那些起承轉合,那還是算了吧。
還有不知從何時開始,我有時候會把背景交代拿來當日記寫,在那邊碎碎念。
反正,我本來就開始不想再寫第一類的教學筆記了。一些知識上的缺漏和修正,自己看看記得就好。和 AI 聊完後更不想寫了,決定就把筆記單純當作學習的副產物吧。
不過前幾天在 Oracle 11g 環境下遇到一個詭異情境,想想乾脆還是把這篇寫出來好了。
SQL Server 的日期時間型別
以下有涉及到 SQL Server 的部分是以 SQL Server 2025 為主。
在 SQL Server 中,我們常用的日期時間型別與對應的目前時間函數如下表:
| 型別 | Range (範圍) | 精度 (Precision) | 目前時間函數 | 說明 |
|---|---|---|---|---|
| datetime | 1753-01-01 ~ 9999-12-31 | 3.33 毫秒 (0.00333秒),會進位 | GETDATE() | 舊系統產物。毫秒非連續,會進位到 .000、.003、.007。 |
| smalldatetime | 1900-01-01 ~ 2079-06-06 | 1 分鐘 | GETDATE() | 極少用。秒數會被「四捨五入」進位到分(29.998秒捨去, 29.999秒進位)。 |
| datetime2 | 0001-01-01 ~ 9999-12-31 | 100 奈秒 (可自訂 0~7 位小數) | SYSDATETIME() | 新專案首選。精度更高且範圍更廣,預設精度為 7 (100奈秒)。 |
| datetimeoffset | 0001-01-01 ~ 9999-12-31 | 100 奈秒 (可自訂 0~7 位小數) | SYSDATETIMEOFFSET() | 包含時區偏移量 (+14:00 到 -14:00),適合跨國應用。 |
TIP
實務上,我只推薦使用 datetime2 和 datetimeoffset(若有時區需求)。
smalldatetime 的範圍太小(2079 年就爆),雖然看似遙遠,但難保不會成為下一個「千年蟲」陷阱。 而 datetime 既然已有更優秀的上位替代 datetime2,就沒有理由回頭使用了。 此外,從 Oracle 遷移到 SQL Server 時,常遇到 Oracle 資料包含早於 1753 年的日期,若使用 datetime 會導致寫入失敗,這也是應選用 datetime2(支援到 0001 年)的另一個重要原因。
關於精度的選擇 (0)、(3)、(7)
datetime2 和 datetimeoffset 都可以設定時間精度為 0 ~ 7 (例如 datetime2(3))。雖然能自訂,但實務上比較常見的選擇是以下三種:
精度
(0)- 秒:- 場景:不需要高精度的顯示需求,或非高併發的建立時間。
- 考量:很多時候畫面只顯示到「秒」,如果資料庫存到「毫秒」,使用者拿畫面上的時間去查詢會查不到資料。設定為
(0)可以避免這種前端顯示與後端儲存不一致的問題。
精度
(3)- 毫秒:- 場景:業界通用標準,大多數程式語言(如 JavaScript
Date)的預設精度。 - 考量:兼顧了效能與足夠的解析度。在高併發場景下,能提供基本的執行順序判斷。
- 場景:業界通用標準,大多數程式語言(如 JavaScript
精度
(7)- 100 奈秒 (預設值):- 場景:極高精度的科學運算或系統紀錄。
- 考量:與 C#
DateTime.Ticks的精度一致。但需注意硬體時鐘是否真能支援到此解析度,否則只是存了一堆無意義的尾數。
WARNING
這裡提到的精度預設值 (7),是指 SQL Server 在 datetime2 型別定義上的預設。
若是透過 Entity Framework Code First 建立,如果不顯式指定精度,其預設行為可能會隨版本或 Provider 而異。強烈建議不要依賴框架的預設值,應明確指定精度(例如 .HasPrecision(0)),以免未來升級或遷移時發生非預期的行為。
精度與一致性的兩難
當我們追求極高精度(如精度 7)時,需要先解決一個前置問題:時間來源的統一性。
假設你的應用程式中,有多個地方需要記錄「現在」這個時間點:
- 每個地方各自呼叫
DateTime.Now? - 還是統一由某處取得一次,然後傳遞給需要的地方?
- 或是直接讓資料庫透過
DEFAULT GETDATE()或Trigger自動填入?
在低精度(如精度 0 或 3)下,這些差異可能不明顯。但當精度提高到 7(100 奈秒)時,每次呼叫 DateTime.Now 之間的微小時間差就會被放大,導致同一筆交易中不同欄位的時間戳記出現不一致。
所以選擇高精度時,可能要先想好時間該怎麼產生:
- 統一由應用程式層產生一次,並傳遞給所有需要的地方?
- 還是交給資料庫層自動產生(但應用層
SaveChanges前就無法得知時間)? - 在分散式環境下,如何處理不同伺服器的時鐘誤差?
這不只是資料庫能存多細的問題,更要看你的應用程式架構能控制到什麼程度。沒有事先定好規範,高精度反而可能暴露出更多不一致的情況。
時間來源的選擇:應用層 vs 資料庫層
TIP
以下說明以 DateTime.Now 對應 GETDATE() 為例,但相同概念同樣適用於 DateTime.UtcNow (對應 GETUTCDATE()) 或 DateTimeOffset.Now (對應 SYSDATETIMEOFFSET())。
在 Entity Framework 有一個比較需要注意的地方是,以下兩者產生出來的 SQL 語法其實不太一樣。
// 方式 A:直接在 LINQ 中使用 DateTime.Now,視 Provider 實作可能會被轉譯為 GETDATE()
db.Table.Where(x => x.RecordTime == DateTime.Now);
// 方式 B:將 DateTime.Now 存入變數,作為參數傳入
DateTime now = DateTime.Now;
db.Table.Where(x => x.RecordTime == now);我之前在工作上都會建議同事寫後者(方式 B)。這有幾個考量點:
首先,在非分散式的架構中,我比較偏好將 時間處理統一在應用程式層,而非資料庫層。這樣可以避免應用程式伺服器與資料庫伺服器兩者時間不同步的問題。
雖然說理論上環境應該要校時,但我也確實遇過兩邊時間不一致的狀況。當然我不會笑話這種情況,畢竟以我對 Infrastructure 一竅不通的程度,真發生要讓我處理可能也處理不了。
其次,如果有涉及到時間運算,最好能在應用層把時間算完。雖然說如果欄位有設 Index,不論是 RecordTime = @d、RecordTime = GETDATE() 或是 RecordTime = DATEADD(MINUTE, 1, GETDATE()) 理論上都吃得到 Index。
但在複雜的運算下,到底會產生什麼 SQL 結果具有一些不確定性。早期 Entity Framework 6 的 Expression 在日期處理上很容易出問題;現在 Entity Framework Core 雖然支援能力比較好,但也發生過「本來可以產生 SQL,但後來覺得效能不好,某版開始決定不再支援」導致報錯的情況。
至於效能考量,只要有吃到 Index 應該不會有太大差異,實際結果可能要看統計資料狀況,以及執行計畫和查詢參數值的相符程度。
WARNING
SQL Server 中,對欄位進行運算(如 DATEADD(MINUTE, -1, RecordTime) = GETDATE())會導致 SARGability (Search ARGument ABility) 失效,使索引搜尋(Index Seek)退化為索引掃描(Index Scan)。
前面提到盡量在應用層處理時間,除了上述 EF 的考量外,我之所以後面會寫這篇,主要是我在 Oracle 11g 遇到的一個特殊案例。
我之前看到一段查詢條件:
RecordDate >= (TO_NUMBER(TO_CHAR(SYSDATE, 'YYYYMMDD')) - 19110000) OR RecordDate = 0;很神奇的是,RecordDate 確實有 0 的值,它又是用 OR 連接,照理說應該要可以撈出那些為 0 的資料,結果卻查不出來。
然後我改成以下寫法,就可以查到資料:
RecordDate = 0 OR RecordDate >= (TO_NUMBER(TO_CHAR(SYSDATE, 'YYYYMMDD')) - 19110000);
-- 或是直接寫死數值
RecordDate = 0 OR RecordDate >= 1150212;當然新版的資料庫可能改善這問題了(應該吧...),這年頭雖然少見,但也不是沒有老舊專案活著。如果能在程式端處理,盡量在程式端處理,也可以減少這個狀況發生。
時間區間的閉合處理
我在 Code Review 看到同事這樣寫時,通常都會建議改掉:
// ❌ 不推薦的寫法
DateTime endTime = input.EndTime.AddTicks(-1);
db.Table.Where(x => x.Time >= input.StartTime && x.Time <= endTime);我會建議改成:
// ✅ 推薦寫法
db.Table.Where(x => x.Time >= input.StartTime && x.Time < input.EndTime);會這樣建議主要有三個考量:
- 語意上更為清楚。
- 更具通用性:用
>=和<,可以用在date、time和DateTime。如果真的要包含結束時間,改個比較運算符號就好。 - 精確度問題:大部分情況下可能不會用到精度
(7)。尤其有些公司專案是用datetime而不是datetime2。但AddTicks(-1)操作的是 100 奈秒(精度7),當兩邊精確度不一樣時,直覺告訴我會有問題。
不過當下沒研究那麼細,問 Claude 也沒指出問題,我也不能憑直覺就說有問題要對方改,只能「建議」而沒有強制(不過現在 AI 倒是都可以明確說出有問題就是了)。
後續有空實際去驗證完後,就不管它了。
畢竟我前面也說了,我本身不會這樣寫;如果真的這樣寫,大部分也是業務邏輯複雜,又受限於當時的專案架構設計。
時間精細度問題
SQL Server 的 datetime 雖然有到毫秒,但他最後位數的值只會有 0、3、7。
這會有什麼精度問題呢?最簡單的測試方式就是,我建一張表,然後把時間存成 datetime:
CREATE TABLE Test (
ID INT IDENTITY(1,1) PRIMARY KEY,
RecordTime DATETIME -- 注意這裡是 DATETIME
);
CREATE INDEX IX_Test_RecordTime ON Test(RecordTime);
-- 插入一筆「整點」的時間
INSERT INTO Test (RecordTime) VALUES ('2026-02-10 08:00:00.000');然後用以下 SQL 查詢:
-- 宣告一個只差 1ms 的時間
DECLARE @d DATETIME = '2026-02-10 07:59:59.999';
SELECT * FROM Test WHERE RecordTime = @d;兩邊時間不一樣,正常應該查不出來對吧?但實際的結果就是這筆資料會被查出來。 因為 datetime 時間精度問題,它會把 '2026-02-10 07:59:59.999' 進位到 '2026-02-10 08:00:00.000'。
當然如果宣告是用 datetime2,就不會有這個問題。但若資料庫型別是 datetime,而變數型別用 datetime2(C# 的 DateTime 預設轉過去通常視為高精度),這會造成效能問題。
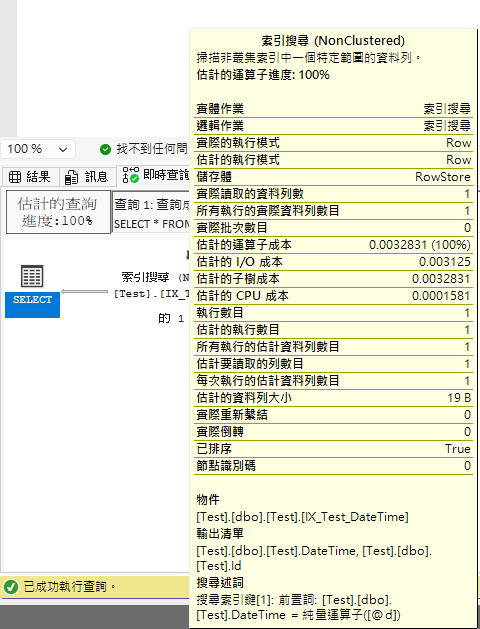
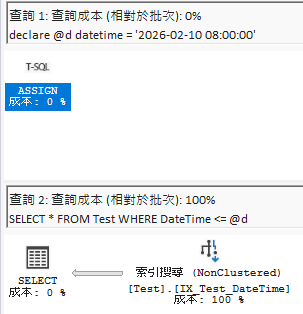
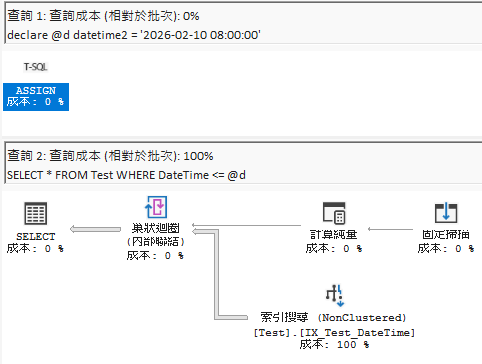
這邊簡單測了一下,兩者在 = 的執行計畫看起來沒什麼差異(SQL Server 有特別優化),但跑 <= 時,那個差異連我這不懂執行計畫的人都能看出來了。
以下是 datetime2 參數查詢 datetime 欄位的執行計畫比較:
使用 = 比較時(兩者執行計畫相同,SQL Server 有優化):
使用 <= 比較時(可以看到明顯的差異):
不過除非是手動維護 SQL,不然不論是 Code First 或是反向工程,都應該不會出現型別不一致,這在用 Dapper 或 ADO.NET 比較常見。
當然如果覺得資料庫型別用 datetime2(7) 就能規避,那我也只能說某些情境下照樣踩雷。
ADO.NET 若沒特別設定 Parameter 型別,DateTime 預設對應的是 datetime。也就是發生「宣告 datetime 變數去查 datetime2(7)」的情況:同一個值,但變數那邊進行進位,資料庫是原值,所以查不到。
像黑暗執行緒 SQL DateTime 型別陷阱 這篇就有一個測試結果,不過他文中說的:
推究原因應是 Dapper 處理 INSERT 及 WHERE 時 @d 對應成 SQL DateTime 型別而非 DateTime2 來回處理過程產生誤差。
更準確的說法是,Dapper 底層依賴的是 ADO.NET,所以本質上還是 ADO.NET 型別推斷的機制導致的。
也就是說,當使用 Entity Framework 時,除非時間精度是設到 (7),否則這種 AddTicks(-1) 的寫法用 <= 只會誤判(包含到非預期的下一秒資料)。
如果不是用 Entity Framework,你沒設定 Type,一樣容易出問題。所以結論就是:乖乖用 <(小於)來做區間查詢吧。
異動歷程
- 2026-02-12 初版文件建立。